
This case study provides a concrete example of the gaps that can occur in standard cataloging practices and their impact on information seeking. It explores an instance of using Linked Open Data (LOD) technologies to address representation gaps, uncovering both opportunities and risks when such interlinking relies on standard vocabularies, which typically represent only mainstream narratives.
By Karen Li-Lun Hwang, Digital Projects and Metadata Librarian, Metropolitan New York Library Council, New York City, New York
The framework for this case study was an 8-month linked open data research fellowship sponsored by the Metropolitan New York Library Council (METRO) in 2016-2017. The fellowship sought to highlight the value afforded researchers and the general public through the application of Semantic Web technologies to cultural heritage resource records. The research focused on resource metadata from a wide range of cultural heritage digital collections in New York City held by various libraries, archives, community organizations, and museums. The project exposed gaps in the knowledge platforms that provide the infrastructure for cultural heritage linked open data work, in particular an imbalance of representation among the common controlled vocabularies used to create linked data. Because the development principle of Semantic Web technologies is to improve information discovery by enabling more precise search as well as data reuse on the web, the findings of my research indicate that such an imbalance threatens to reify and amplify the same cultural privileging that exists already in society as a whole.
Context and Background
My initial exposure to digital collections was in 2007 as an employee of the Asian American Arts Centre (AAAC), a small arts organization in Lower Manhattan that for decades had promoted the careers of Asian American artists. With a loss in visitors to its gallery in the wake of 9-11, AAAC was awarded a grant to help preserve its history and extend its work through the creation of a digital archive. This organization, therefore, can be characterized as an arts promotion organization, not a one focused on cultural heritage preservation, even though the digital archive was to be based on physical ephemera and reproductions of art work in various media collected by the organization through the decades. At the time, the decision had been made to conform descriptive practices for the digital archive to the standards of the field in order to ensure its use as an educational resource and the potential interoperability of its records with other systems. We spent a considerable amount of time manually looking up Getty terms in its online Art and Architecture Thesaurus (AAT) and Union List of Artist Names (ULAN) as we cataloged, often applying suggested preferred terms we found there. We also developed our own local vocabulary consisting, for example, of names of artists and terms that could not be found in ULAN or AAT, names and terms such as “Rivington School”, “Godzilla”, “Tomie Arai”, “Kwok Mang Ho”, or “wabi sabi”, as well as other new terms if we absolutely refused to compromise on the term we ourselves preferred, such as “internment” (instead of “concentration camps”) or “mixed race” (as opposed to “multiracial”).
Years later, however, reflecting on our work, I and others began to wonder why we, as an organization grounded in conversations of identity politics and self-determination, had bothered to apply terms from these standard controlled vocabularies. Data normalization on our platform was understandable to facilitate the end user’s ability to navigate our records, but using these authority terms had not provided any gains in discoverability, especially since search engines have a limited ability to crawl and index repository databases. And by adhering to ‘preferred terms’ in standard vocabularies we applied language that was often neither intuitive to us nor arguably to the expected audiences on our own platform. These questions drew me to further explore tools or alternatives in library practices that would yield tangible gains.
With a focus on structuring information in a way to enable the origin-agnostic interlinking of data across the web, the principles of linked open data are widely seen as addressing many of these practical discoverability concerns through the application of what are known as ontologies and entities in the form of URIs (comparable in their relation to resource objects to the application of terms and elements from schema and standardized controlled vocabularies). The publication of information using Semantic Web technologies enables–given semantic assignment is accurate–the automated collation and graphing of information across the web. An example of this might be some of the information powering Google’s graph of knowledge, enabling Google to present the information boxes on subjects that often appear as part of any search result. The inherent gains that linked open data seems to offer led me to explore possibilities for its implementation, first as part of the group Linked Jazz and later through a fellowship project with the regional state library council Metropolitan New York Library Council (METRO) that I called “Interlinking Resources, Diversifying Representation: Linked Open Data in the METRO Community”. This fellowship project is the source of this case study.
“Interlinking Resources, Diversifying Representation: Linked Open Data in the METRO Community” sought to use linked open data to interlink resource records across METRO’s diverse GLAM (galleries, libraries, archives, museums) community in New York City for a single subject, in this case, the New York-based artist Martin Wong. As a figure who interacted with many distinct communities in New York City and thematized his gay and Asian American identity in his work, and as an artist who has gained recognition in the art world, Martin Wong is represented in the collections of many institutions, each serving to highlight a different facet of the artist. These distinct facets are represented not only by the resources themselves, but also within the resource metadata of the institutions that lean towards each individual institution’s purview: modern artist, Downtown NY artist, American artist, Asian American artist. Both as a group of resources and as a composite pool of descriptive metadata, this draws a more complex portrait of the artist than any one institution alone can. Conceptually, the goal of the proposal was not only to canvas existing cultural heritage linked open data work practices in repository work, but to also illustrate the importance in designing pathways for smaller organizations to be part of this movement in order to ensure that more nuanced portraits of subjects are maintained.
Descriptive Analysis
For the research project, I acquired metadata from over 110 resource records that included Martin Wong in its metadata from a group of institutions covering a range of institution types, all members of METRO with the exception of the New Museum:
- Asian American Arts Centre
- Brooklyn Museum
- Brooklyn Public Library
- Fales Library and Special Collections, NYU
- Museum of Modern Art (MOMA)
- New Museum
- New York Public Library
- NYARC (library consortium of MOMA, The Frick Museum, and Brooklyn Museum
- Whitney Museum Library
- Whitney Museum
Once the data models and systems in use by each institution were assessed, the metadata was retrieved and in some instances expanded1 for these Martin Wong materials, which included exhibition catalogs, ephemera from exhibitions, finding aids, collaborative works, and anthologies. I then began the work of creating linked open data. Linked data is often described as “things not strings”, which focuses on concretely identifying a concept, person, or thing by an unambiguous and stable URI that represents a record of that person in a vocabulary or database, rather than a value string like a name that can be mistaken for something else. With resource records, an example of this would be putting “http://id.loc.gov/authorities/names/n87920430, Martin Wong’s record in the Library of Congress Name Authority File (LCNAF) or “http://www.wikidata.org/entity/Q1522057, his record on Wikidata, in the creator field of a record, instead of just “Wong, Martin” or “Martin Wong”. If records across institutions all use linked open data to identify Martin Wong in their metadata, then across these repositories, these records can be associated with one another and the data from these records can be interlinked by machine processes. The process of converting string values into entity URIs is called entity reconciliation. My first step, therefore, was to reconcile names from the resource metadata to interlinkable name entity URIs in standard controlled vocabularies and knowledge bases, using the popular tool for working with data, OpenRefine.2 The particular findings from this reconciliation work are the subject of this case study.
In reconciling names, I targeted name entity URIs from the Library of Congress due to its widespread use in cataloging cultural heritage materials, the Getty’s Union List of Artist Names (ULAN), frequently the preferred choice for art resource description, and Wikidata, an open data platform and sister project to the popular Wikipedia, that OpenRefine developers are at the moment increasingly building into OpenRefine’s reconciliation capabilities3. The result of this reconciliation process exhibited patterns of inequality in representation and visibility similar to those found in society. Broadly described, those whose contexts intersect more mainstream narratives or stem from the collections of more mainstream institutions disproportionately could find a matching term among these controlled vocabularies, whereas those belonging to more marginalized narratives disproportionately could not. For example, with the Martin Wong records from larger libraries holding primarily bibliographic materials, a high percentage of names could be reconciled in at least one, if not all the sources used, with the exception of names from resources that may appear more thematically “fringe”, such as some artists from the exhibition catalog “Art in the Streets” on graffiti art, held both by NYARC and NYPL. Another example was the anthology “Fresh talk, daring gazes : conversations on Asian American art”, held by the Whitney Library and NYARC, where some authors and artists were not represented in these vocabularies, either. Other examples were names from resource records for primary source materials, finding aids, and exhibitions from Fales Library, New Museum, and Asian American Arts Centre, all of which represent very specific, arguably “living” art narratives, with the majority of names not found coming from the Asian American Arts Centre.
This disparity is represented clearly by these network graphs created from this reconciliation work, where names are grouped by institution, which as argued above can be seen to represent a different framework for the artist Martin Wong’s career. Figures 1 and 2 represent all the available names in the metadata, whereas Figure 3 shows names not found.
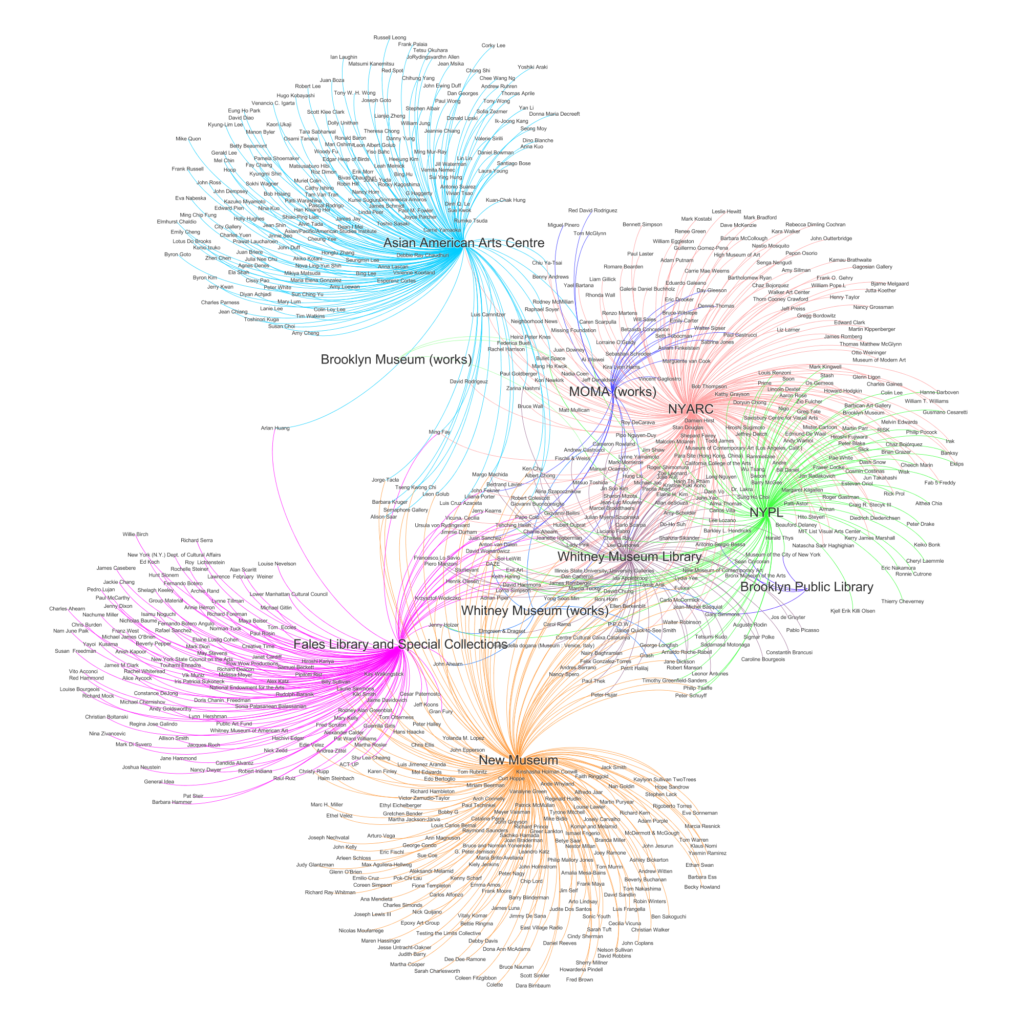
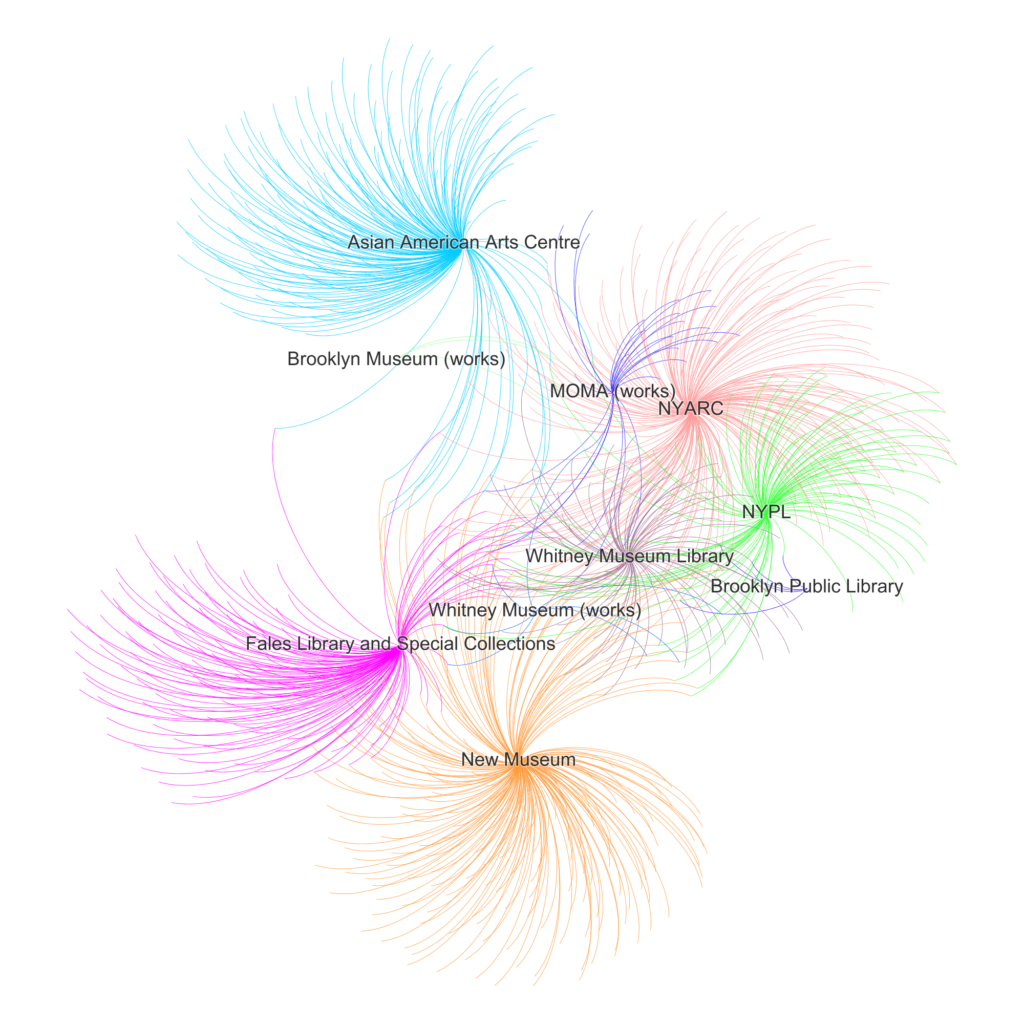
This unevenness in the ability to reconcile terms to name entity URIs precipitates critical repercussions for the information landscape, given that ideally, unambiguous semantic interlinking and aggregation of data relies on the identification of information components by URI. These repercussions include:
- More popular artists, and by extension, certain narrative frameworks, will have a stronger association with Martin Wong and be more discoverable;
- Those privileged frameworks and associations will be disproportionately amplified, since they are readily available for interlinking and reuse. In other words, those contexts for Martin Wong and the people comprising those contexts can constantly be repurposed in their relationship to Martin Wong using Semantic Web technologies, while the others can not.
Results and Recommendations
These findings may seem to raise serious doubt about the effectiveness of linked open data, given these gaps. But the Semantic Web is happening and continues to evolve. As information professionals we are only too aware that the majority of information seekers, including students and researchers expressly generating new knowledge, use internet search as a–if not primary, then at least a preliminary–means to connect with resources. We need to meet users where they are at and ensure that the breadth of materials available can actually be found through search and try to close the gaps in both coverage and discoverability on the web. Knowing that these gaps exist, linked open data can instead be seen as an opportunity to actively reshape the landscape of data linkages across the cultural spectrum.
There are two areas of focus I see for us as a community of practitioners to begin addressing these gaps:
- The development of open platforms and tools to facilitate the expansion of terms that can be found in the linked open data cloud, for example, the enablement of archives and libraries to contribute their local controlled vocabularies;
- Education about the gaps and biases that exist in datasets, and in the case of linked open data, the importance of contributing knowledge to safeguard against the further amplification and privileging of some narratives before others that can occur through the fact that linked open data enables reuse.
As open platforms for contributing knowledge, Wikidata and Wikipedia clearly provide a strong means for mending these gaps.4 It is an advantage, as well, that linked open data is automatically generated when articles and records are submitted without requiring any technical knowledge of how to create linked open data. Currently, however, the actual writing of articles and contribution of data remain relatively steep learning curves. The development of simpler tools and especially tools that accommodate typical cataloging workflows, such as building the capability to contribute vocabularies to Wikidata/Wikipedia into collection management software, would help support these activities. In terms of outreach, we should raise awareness that in contributing knowledge through such platforms, we are not only mending gaps in knowledge, but we are also building a more inclusive graph of knowledge for others to connect up with and connect into to ensure a more diverse information landscape on the web.
 Print This Page
Print This Page
Footnotes
- https://www.getty.edu/research/tools/vocabularies/ulan/index.html
- The details of the project itself can be read in my final blogpost for the project “The Vision of Linked Open Data: Martin Wong and the METRO Network”, August 17, 2017 (https://mnylc.org/fellows/2017/08/03/lod_metro/). I have also written a blogpost on using OpenRefine’s reconciliation services here: (https://mnylc.org/fellows/2017/03/17/using-openrefine-to-reconcile-name-entities/)
- For ULAN and LCNAF, reconciliation was performed by retrieving linked data for names from the Virtual International Authority File (VIAF), which links records for a person or title from many different national libraries and similar databases into a single cluster record.
- Another example of an open platform for the creation of linked open data that I have worked with would be the more music domain-specific database MusicBrainz.
